






ENTERPRISE
Architecture overview
-
Last updated: July 3, 2023
-
Read time: 2 Minutes
The following diagram shows the core components of Burp Suite Enterprise Edition and the connections between them.
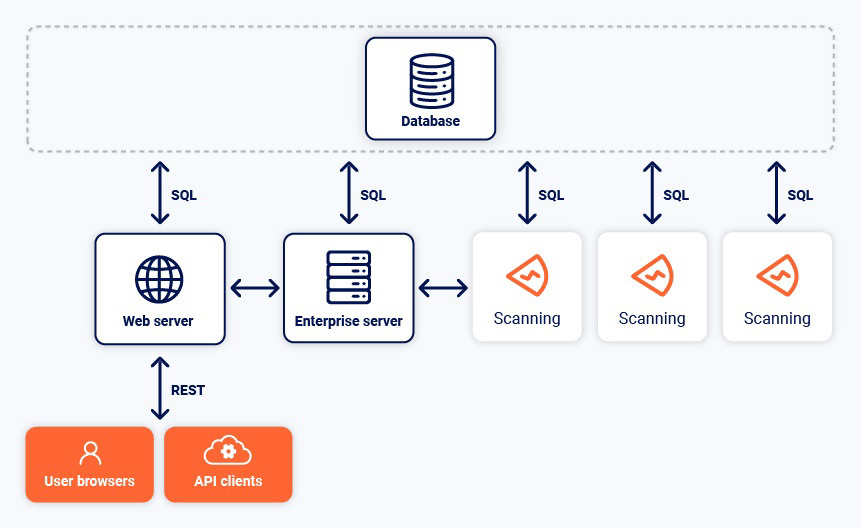
Enterprise server
The Enterprise server is the main application server. It coordinates between the other components. The Enterprise server is always installed on the same machine as the web server.
Web server
The web server provides the interface to users either via the web UI or one of the APIs. The web server is always installed on the same machine as the Enterprise server.
Database
Burp Suite Enterprise Edition uses a SQL database to store data about configured sites and scans, the results of scans, and other configuration information. You can use one of the following options:
- A bundled database that can be installed on the same machine as the Enterprise server and web server. This option is suitable for a trial or evaluation. For production deployments we recommend that you use your own external database.
- Your own external database. This option lets you utilize any existing database infrastructure that you have, including database backups, and is more appropriate for larger deployments. For information about specific database types and versions that are supported, please refer to the database specification.
Note that you can start out using the bundled database and migrate to an external one later if necessary. We recommend this approach in order to simplify the initial installation and evaluation process.
Read more
Migrating to an external databaseServices
Burp Suite Enterprise Edition installs either 3 or 4 services on your machine depending on whether you're using the bundled database or not. For more information, please refer to the corresponding documentation.
Read more
Burp Suite Enterprise Edition servicesScans and scanning machines
On standard deployments, scans run on a scanning machine. You can embed the scanning machine on the same machine as the other components, or you can deploy multiple external machines on which your scans can run. Scanning machines are grouped into scanning pools, to allow finer control over scanning resources.
Read more
What is a scanning machine?On Kubernetes deployments, you don't have to set up and manage individual scanning machines. Instead, the system automatically creates additional resources to cope with the number of concurrent scans that you need to run at any given time. These resources are then scaled back down again once they are no longer needed.